度量学习之三元组损失
Schroff F, Kalenichenko D, Philbin J. Facenet: A unified embedding for face recognition and clustering[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2015: 815-823.
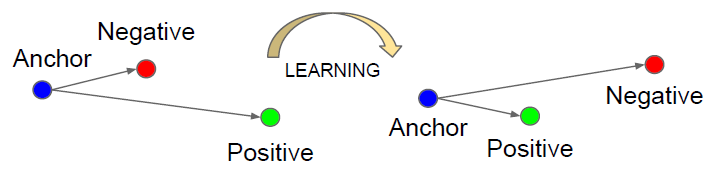
这篇论文虽然是是用在人脸识别上的,但是行人重识别中的一个影响力十分大损失函数——triplet loss就是在这篇论文中提出的,之前用到的对比损失(contrastive loss)能够起到缩小类内距离,增大类间距离的作用,从而通过距离判断两类相似与否。但是contrastive loss有一个痛点,就是我们无法约束类间距离和类内距离的大小,虽然缩小了类内距离,也扩大了类间距离,但是类内距离仍然可能比类间距离大,这就是contrastive loss的局限性。由此作者想到增加一个类内距离比类间距离小的约束,于是三元组诞生了,如下图所示: